Golang是否真的没有指针运算?
答案是肯定的: 没有指针运算(哈哈, 别着急慢慢往后面看)
func main() {
a1 := []int{1, 2, 3}
p1 := &a1[0]
fmt.Println(reflect.TypeOf(p1)) // *int
fmt.Println("p1: ", *p1) // 1
fmt.Printf("p1 address:%p\n", p1) // 0xc00009a000
p1 = p1 1
}
invalid operation: p1 1 (mismatched types *int and int)
C或者C 转golang同学就高兴了, 再也不用面试的时候去面对下面这道题了(面试C 的时候, 基本每家公司的笔试题上都会有这道题)
#include<stdio.h>
void main()
{
int a[5]={1,2,3,4,5};
int *ptr=(int *)(&a 1);
printf("%d,%d",*(a 1),*(ptr-1));
}
这题的结果是: 2和5
可惜高兴的太早了. golang虽说指针变量不能直接参与指针运算, 但是却提供了unsafe包, 能够实现同样的功能
Unsafe
Pointer
type ArbitraryType int
type Pointer *ArbitraryType
这里特别要注意ArbitraryType在这里只起到文档作用, 不是代表是真正的int. 比如: Sizeof等相关的函数可以接受任意类型的变量, 假如按照int类型来解释, 基本就解释不通了. 官方文档特别提示这个
ArbitraryType is here for the purposes of documentation only and is not actually part of the unsafe package.
It represents the type of an arbitrary Go expression.
a1 := 3.6
fmt.Println(unsafe.Pointer(&a1)) // 0xc000014078
a2 := 3
fmt.Println(unsafe.Pointer(&a2)) // 0xc00007a008
从这里可以看到Pointer可以指向任意类型的变量(跟C的void*类似)
使用Pointer要注意下面4条准则
- 任何类型的指针值都可以转换为Pointer // unsafe.Pointer(&a1)
- Pointer可以转换为任何类型的指针值 // (*float32)(unsafe.Pointer(numPointer))
- uintptr可以转换为 Pointer // unsafe.Pointer(uintptr(nPointer) unsafe.Sizeof(&a) * 3)
- Pointer可以转换为 uintptr // uintptr(unsafe.Pointer(numPointer))
uintptr
type uintptr uintptr
uintptr 是一个整数类型,它足够大,可以存储. 只有将Pointer转换成uintptr才能进行指针的相关操作
但下面的代码要注意, 这种用法是错误的
tmp := uintptr(unsafe.Pointer(&x)) unsafe.Offsetof(x.b)
pb := (*int16)(unsafe.Pointer(tmp))
*pb = 42
uintptr是可以用于指针运算的,但是GC并不把uintptr当做指针,所以uintptr不能持有对象, 可能会被GC回收, 导致出现无法预知的错误. Pointer指向一个对象时, GC是不会回收这个内存的.
相关函数
- func Sizeof(x ArbitraryType) uintptr
- func Offsetof(x ArbitraryType) uintptr
- func Alignof(x ArbitraryType) uintptr
Sizeof
返回类型x所占据的字节数, 但是却不包括x所引用的内存. 例如: 对于一个指针,函数返回的大小为8字节(64位机上),一个slice的大小则为slice header的大小
var a int32 = 10
t := unsafe.Sizeof(a)
fmt.Println(t)
var b string = "test"
fmt.Println(unsafe.Sizeof(b))
type aa struct {
B bool
C uint64
}
c := aa{}
fmt.Println(unsafe.Sizeof(c))
type bb struct {
B *bool
}
c1 := bb{}
fmt.Println(unsafe.Sizeof(c1))
4 // 这个没啥说的, int32在64位机器上占4个字节
16 // Sizeof(string)占计算string header的大小, struct string { uint8 *str; int len;}
16 // 这个涉及到内存对齐的问题(C, C 同学是不是又想到曾经虐我们千百遍的面试题了...). 内存对齐的问题下面再说
8 // 指针占8个字节(64位机器)
Offsetof
返回结构体中某个字段的偏移量, 这个字段必须是structValue.field形式. 也就是返回结构体变量的开始位置到那个字段的开始位置之间字节数.
type aa struct {
B bool
C uint64
}
c := aa{}
fmt.Println(unsafe.Offsetof(c.B), unsafe.Offsetof(c.C))
B:0
C:8
注意这里C:8是不是结果错了? 其实不然, 这是因为涉及到内存对齐的问题
Alignof
这个函数返回内存对齐时的对齐值, 这个跟内存对齐有关
type Part1 struct {
a bool
b int32
c int8
d int64
e byte
}
part1 := Part1{}
fmt.Printf("part1 size: %d, align: %d\n", unsafe.Sizeof(part1), unsafe.Alignof(part1))
part1 size: 32, align: 8
内存对齐
关于为什么要内存对齐, 就是为了加快内存的存取速度, 用空间换时间的做法. 我们不需要太过关注这个, 就大概知道golang有这么一个性质.
不同平台类型T内存大小和对齐值都是不一样的. 具体使用的时候要按照自己的本机实际情况为准. 不过大部分面试题或者我们讨论的时候都是按照64位进行的
fmt.Printf("bool: %d\n", unsafe.Alignof(bool(true)))
fmt.Printf("int32: %d\n", unsafe.Alignof(int32(0)))
fmt.Printf("int8: %d\n", unsafe.Alignof(int8(0)))
fmt.Printf("int64: %d\n", unsafe.Alignof(int64(0)))
fmt.Printf("byte: %d\n", unsafe.Alignof(byte(0)))
fmt.Printf("string: %d\n", unsafe.Alignof("xxx"))
fmt.Printf("map: %d\n", unsafe.Alignof(map[string]string{}))
bool: 1
int32: 4
int8: 1
int64: 8
byte: 1
string: 8
map: 8
不只是unsafe.Alignof可以计算内存对齐值, reflect.TypeOf(bool(true)).Align())同样可以
关于普通变量的对齐没啥说的, 就是上面代码那个样子. 但是涉及结构体就变得比较复杂了
type Part1 struct {
a bool // 1
b int32 // 4
c int8 // 1
d int64 // 8
e byte // 1
}
j
part1 := Part1{}
fmt.Printf("part1 size: %d\n", unsafe.Sizeof(part1))
结果是多少呢? 是不是1 4 1 8 1 = 15, 结果并不是. 下面具体分析
对齐规则
- 结构体的成员变量,第一个成员变量的偏移量为 0。往后的每个成员变量的对齐值必须为编译器默认对齐长度(#pragma pack(n))或当前成员变量类型的长度(unsafe.Sizeof),取最小值作为当前类型的对齐值。其偏移量必须为对齐值的整数倍
- 结构体本身,对齐值必须为编译器默认对齐长度(#pragma pack(n))或结构体的所有成员变量类型中的最大长度,取最大数的最小整数倍作为对齐值
- 结合以上两点,可得知若编译器默认对齐长度(#pragma pack(n))超过结构体内成员变量的类型最大长度时,默认对齐长度是没有任何意义的
首先我们要知道struct, slice内存都是连续的
| 成员 | 类型 | 默认对齐值 | 偏移量 | 解析 | 内存布局 |
|---|---|---|---|---|---|
| a | bool | 1 | 0 | 第一个成员的偏移量是0, 占用1位 | a |
| b | int32 | 4 | 1 | 根据规则1, 对齐值是当前成员类型的对齐值, 所以偏移量是4的整数倍, 所以需要先补3位(2-4), 再第5位开始填充 | axxx|bbbb |
| c | int8 | 1 | 8 | 根据规则1, 偏移量是对齐值的整数倍, 8/1 = 8, 故不需要偏移, 从第9位开始填充1位 | axxx|bbbb|c |
| d | int64 | 8 | 9 | 根据规则1, 偏移量是对齐值的整数倍, 故需要先补7位(9-16), 从17位开始填充8位 | axxx|bbbb|cxxx|xxxx| dddd|dddd |
| e | byte | 1 | 24 | 根据规则1, 24/1= 24, 不需要偏移, 从25位开始填充 | axxx|bbbb|cxxx|xxxx| dddd|dddd|e |
| 最终调整 | struct | 8 | 25 | 根据规则2, 结构体的的对齐值是8, 由于目前的偏移量是25, 不是8的整数倍, 故需要填充至8的最小整数倍, 同时比25大, 故是32 | axxx|bbbb|cxxx|xxxx|dddd|dddd|exxx|xxxx |
有的时候我们调整机构体字段的顺序是可以节省内存的
type Part1 struct {
a bool
b int32
c int8
d int64
e byte
}
type Part2 struct {
e byte
c int8
a bool
b int32
d int64
}
func main() {
part1 := Part1{}
part2 := Part2{}
fmt.Printf("part1 size: %d, align: %d\n", unsafe.Sizeof(part1), unsafe.Alignof(part1))
fmt.Printf("part2 size: %d, align: %d\n", unsafe.Sizeof(part2), unsafe.Alignof(part2))
}
part1 size: 32, align: 8
part2 size: 16, align: 8
看到这里, 基本就解释了Sizeof, Offsetof涉及到内存对齐的问题. 这里详细解释一下
type aa struct {
B bool
C uint64
}
c := aa{}
fmt.Println(unsafe.Sizeof(c))
fmt.Println(unsafe.Offsetof(c.B), unsafe.Offsetof(c.C))
| 成员 | 类型 | 默认对齐值 | 当前偏移量 | 解析 | 内存布局 |
|---|---|---|---|---|---|
| B | bool | 1 | 0 | 第一个成员的偏移量是0, 占用1位 | B |
| C | uint64 | 8 | 1 | 由于偏移量必须是对齐值的整数倍, 所以需要补位(2-8), 从9位开始填充 | Bxxx|xxxx|CCCC|CCCC |
所以结果是: unsafe.Sizeof(c) = 16, unsafe.Offsetof(c.C) = 8
关于更详细关于内存对齐, 请参考煎鱼博客
实际使用场景
转换类型
func Float64bits(f float64) uint64 {
return *(*uint64)(unsafe.Pointer(&f))
}
计算偏移量
func main() {
type aa struct {
B bool
C uint64
}
c := aa{}
fmt.Println(c)
aac := (*uint64)(unsafe.Pointer(uintptr(unsafe.Pointer(&c)) unsafe.Offsetof(c.C)))
*aac = 10
fmt.Println(c)
}
{false 0}
{false 10}
验证slice子切片和母切片共享底层数组
总看到slice子切片和母切片共享底层数组, 下面我们用实际的代码验证一下
func main() {
var s1 = []int{1, 2, 3, 4, 5, 6, 7}
var s2 = s1[2:5]
s1SliceArrayPointer := unsafe.Pointer(*(*unsafe.Pointer)(unsafe.Pointer(&s1)))
fmt.Println("s1[0]:", *(*int)(s1SliceArrayPointer))
fmt.Println("s1 address:", s1SliceArrayPointer)
s2SliceArrayPointer := unsafe.Pointer(*(*unsafe.Pointer)(unsafe.Pointer(&s2)))
fmt.Println("s2[0]:", *(*int)(s2SliceArrayPointer))
fmt.Println("s2 address:", s2SliceArrayPointer)
offset2Pointer := unsafe.Pointer(uintptr(s1SliceArrayPointer) unsafe.Sizeof(&s1[0])*2)
fmt.Println("offset s1[2]:", *(*int)(offset2Pointer))
fmt.Println("offset s1 address:", offset2Pointer)
}
s1[0]: 1
s1 address: 0xc00001a040
s2[0]: 3
s2 address: 0xc00001a050
offset s1[2]: 3
offset s1 address: 0xc00001a050
前提是要先知道slice的结构体
// runtime/slice.go
type slice struct {
array unsafe.Pointer // 元素指针
len int // 长度
cap int // 容量
}
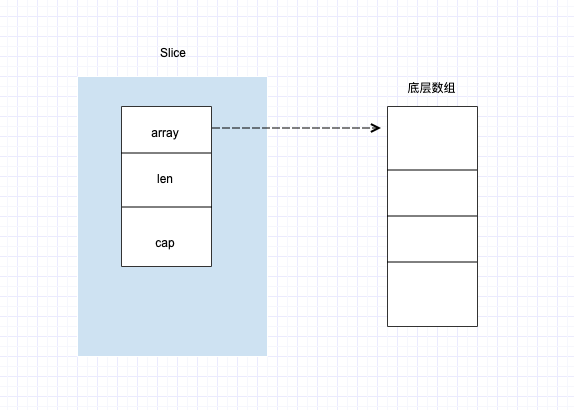
- unsafe.Pointer(&s1) 取到s1的首地址的指针, 其实也就是s1 array位置的指针
- unsafe.Pointer((unsafe.Pointer)(unsafe.Pointer(&s1))) 将s1 array存放的值取出来, 也就是底层数组的首元素的地址
- unsafe.Pointer(uintptr(s1SliceArrayPointer) unsafe.Sizeof(&s1[0])*2) 向后偏移2位, 也就是取到3的位置
我们看到s2的首元素的地址和s1偏移2个位置的地址都是0xc00001a050, 所以也就证明确实是同一个底层数组
结论
golang指针不能参与计算, 但是unsafe包可以
unsafe包绕过了Go的类型系统,达到直接操作内存的目的,使用它有一定的风险性, 正常事情下, 不建议开发的代码中大量引入这个. 但是我们需要知道有这样的黑科技存在!
参考资料
- 官方文档
- 码农桃花源-深度解密Go语言之unsafe
- 煎鱼-有点不安全却又一亮的 Go unsafe.Pointer
- 煎鱼-在 Go 中恰到好处的内存对齐
到此这篇关于“Golang是否真的没有指针运算?”的文章就介绍到这了,更多文章或继续浏览下面的相关文章,希望大家以后多多支持JQ教程网!
您可能感兴趣的文章:
Go语言学习 第五章 运算符和表达式 ①
08-GoLang运算符
go 指针
Golang——运算符和格式化输出
每天一点Go语言——变量、常量、运算符解析
超详细的C 指针介绍及实例教程
Go 语言中的取止运算符"&"貌似有bug
Golang是否真的没有指针运算?
golang runtime 简析
拓展学习-golang的基础语法和常用开发工具