python爬虫多线程如何加速爬取?
发布时间:2020-11-26 编辑:jiaochengji.com
教程集为您提供python爬虫多线程如何加速爬取?等资源,欢迎您收藏本站,我们将为您提供最新的python爬虫多线程如何加速爬取?资源

我们在学习爬取的时候,这是一个非常缓慢的过程,如果不好好处理的话,我们需要花费很长一段时间,去处理,影响其他工作进行,难道只能保持这种状态吗?当然不是,因为有些功能,可以足够让我们去加速进行爬取,不会耽误其他工作进度,想要了解的小伙伴, 就接着看下文很容易学会哦~
一、准备阶段
python3 、多线程库 、第三方库 requests的安装以及调用
二、线程分析图示:
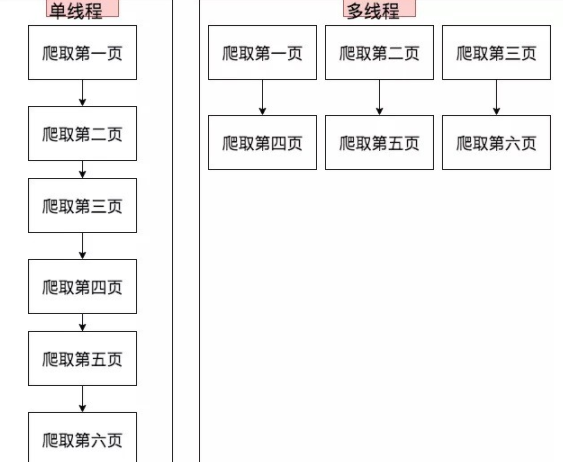
三、多线程加速实现代码演示
import requests
from threading import Thread,current_thread
def parse_page(res):
print('%s 解析 %s' %(current_thread().getName(),len(res)))
def get_page(url,callback=parse_page):
print('%s 下载 %s' %(current_thread().getName(),url))
response=requests.get(url)
if response.status_code == 200:
callback(response.text)
if __name__ == '__main__':
urls=['链接']
for url in urls:
t=Thread(target=get_page,args=(url,))
t.start()如果觉得爬取时候比较慢,就可以按照上述小编教大家的方式去处理哦~可以大大提高爬取效率,如果大家还想了解更多的学习知识,进入python学习网了解即可。
您可能感兴趣的文章:
Python 爬虫学习系列教程
python爬虫一般都爬什么信息
python和爬虫有什么关系
Python2爬虫入门之如何学习爬虫
经典必备之Python爬虫入门(一)
零基础python爬虫需要多久
《Python2爬虫入门教程指南》(系列教程)
python百度反收集如何使用
Python爬虫进阶之Robots协议
如何使用python多线程有效爬取大量数据?
[关闭]