python爬虫之使用user-agent需要注意什么?

之前小编就讲了两个简单的网络请求方法,不过有小伙伴反映还想看看常见的方法是什么。没问题,对于刚来的python小白向来小编都是要满足大家的要求的。今天就我们常见的user-agent方法,小编会讲一下它的使用,同时在过程中展示使用此类方法不足的地方,已经学过的小伙伴也可以看看。
我们在写爬虫,构建网络请求的时候,不可避免地要添加请求头( headers ),以 mdn 学习区为例,我们的请求头是这样的:
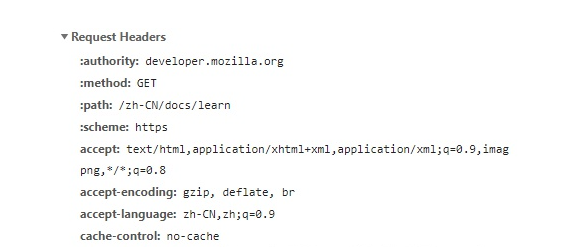
一般来说,我们只要添加 user-agent 就能满足绝大部分需求了,Python 代码如下:
import requests
headers = {
#'authority': 'developer.mozilla.org',
#'pragma': 'no-cache',
#'cache-control': 'no-cache',
#'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 YaBrowser/19.7.0.1635 Yowser/2.5 Safari/537.36',
#'accept': 'text/html,application/xhtml xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
#'accept-encoding': 'gzip, deflate, br',
#'accept-language': 'zh-CN,zh-TW;q=0.9,zh;q=0.8,en-US;q=0.7,en;q=0.6',
#'cookie': 你的cookie,
}
response = requests.get('https://developer.mozilla.org/zh-CN/docs/learn', headers=headers)
但是有些请求,我们要把特定的 headers 参数添加上才能获得正确的网络响应,不知道哪个参数是必要的情况下,就要先把所有参数都添加上,再逐个排除。
但是手动复制粘贴 headers 字典里的每一个键值对太费事了。
可以看出,我们使用常见的user-agent用来作为header的请求还是有一定不方便的地方,我们可以结合之前所讲的两个方法互为补充。更多Python学习推荐:JQ教程网Python大全。
您可能感兴趣的文章:
Python爬虫进阶之Robots协议
Python3爬虫入门:Robots协议
python爬虫一般都爬什么信息
Python 爬虫学习系列教程
python的爬虫是什么意思
《Python2爬虫入门教程指南》(系列教程)
Python2爬虫入门之如何学习爬虫
python怎么做反爬
python爬虫中header是什么?怎么用?
python可以抓取数据吗